
Compilation and deployment
To turn the compile-time entities into runtime
entities, they must be compiled and deployed as an application instance.
To instantiate an application, the user specifies two things: an application
scope and a main operator. The main operator is one of the potential
main operators, which are chosen by the user. A potential main operator
is any composite operator whose connection clause is empty and whose
formal parameters all have default values. In other words, a potential
main has no input or output ports and has no required parameters.
The user picks the main composite when they are compiling the application.
The application scope is a runtime concept, consisting of a set of
application instances, and serves for naming communication partners
in dynamic application composition. The user can pick the application
scope explicitly by using the applicationScope config
directive, or if the scope is omitted, the compiler adds the application
to a default application scope.
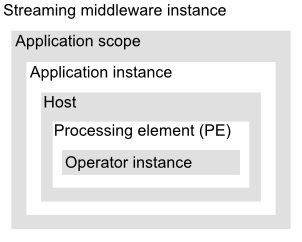
The figure illustrates how all the runtime entities fit together. At the outermost level, there is an instance of the streaming middleware. The streaming middleware hosts one or more application scopes, and each application scope consists of one or more application instances. Each application instance has a main composite operator. To create each application instance, the compiler starts from main, and expands all operator invocations in the graph clause: it expands primitive operator invocations by running their code generator, and it expands composite operator invocations by expanding their graph clause, which in turn might trigger this same expansion process recursively. Only operators reached this way are expanded; if an operator is not directly or indirectly invoked from the main operator, the compiler skips it. The result is a directed graph where vertices are primitive operator instances and edges are streams. There can be multiple operator instances corresponding to a single operator invocation in the source code; this situation happens if the composite operator that contains the operator invocation is expanded multiple times, as is explained in this figure. All expansions happen at compile time.
The compiler might fuse multiple operator instances in the flow graph into units called partitions. The notion of a partition of operator instances in the flow graph is distinct from the notion of a partition in a window; they are unrelated concepts. The execution container for a partition is a processing element (PE). At run time, there is a one-to-one correspondence between partitions and PEs, since each partition runs in exactly one PE. Fusion is relevant for performance because PE-internal communication is faster than cross-PE communication, but multiple PEs can use the hardware resources of multiple hosts. By default, the optimizer does not perform fusion, and places each operator instance in its own PE. Furthermore, users can control fusion with explicit partition placement constraints in the code, as shown in the following example:
int32 foo(rstring s, int32 i) { /*do something expensive*/ return i; }
composite Main {
graph stream<int32 i> In = Beacon() {}
stream<int32 i> A1 = Functor(In) {
output A1 : i = foo("A", i);
config placement : partitionColocation("A"); //fuse A1 into "A"
}
() as A2 = FileSink(A1) {
param file : "A.txt";
config placement : partitionColocation("A"); //fuse A2 into "A"
}
stream<int32 i> B1 = Functor(In) {
output B1 : i = foo("B", i);
config placement : partitionColocation("B"); //fuse B1 into "B"
}
() as B2 = FileSink(B1) {
param file : "B.txt";
config placement : partitionColocation("B"); //fuse B2 into "B"
}
}
The compilation typically involves source code in multiple files.
It starts from an SPL file with the main operator, but must discover
other source files when it expands operator or function invocations.
This file lookup follows the SPLPath, an ordered list of root directories
or toolkit manifests from which to start lookup. A typical implementation
of SPL supports SPLPath specifications with compiler options. For
example, if SPLPath contains /first/root/dir/,
the compiler looks for files that implement namespace com.ibm.my.nameSpace starting
at the directory /first/root/dir/com.ibm.my.nameSpace/.
This directory contains SPL files with functions and composite operators, as well as native
source files with native functions and primitive operators. To be
more accurate, the implementation of a primitive operator has its
own directory, with at least one generic subdirectory for code that should
work on all platforms, and possibly also platform-specific directories.
As of now, SPL assumes homogeneous hardware on the hosts that are
employed by the streaming middleware.
While configuration options can appear in many places in the code (see the topic Config clause in Operator invocations and the topic Config clause in Operator definitions), certain configurations typically appear only in a composite operator that is intended as the main composite operator in an application instance. The following example shows some of those configuration options:
composite SourceSink { // main
graph
stream<int32 i> A = FileSource() { param file: "a.dat"; }
() as Sink = FileSink(A) { param file: "b.dat"; }
config
logLevel : trace;
hostPool : SourcePool = ["localhost", "10.8.5.6"];
defaultPoolSize : 5;
}