
Context
The Group or Context component hosts all functions which need access to all records from all chains or subset of chains, in order to implement record correlation.
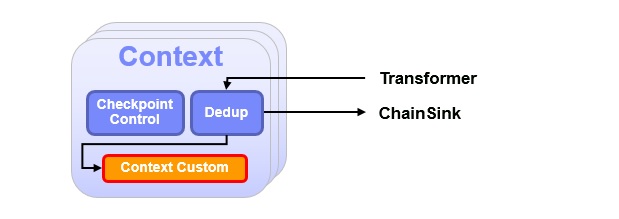
Use this component if you want to use the built-in record deduplication or if your use case requires custom correlation logic. Both features can only be used if you configured the ITE application for variant B or C.
Record deduplication
The built-in record deduplication checks each record if it has been processed before. A certain attribute of the record schema will be set to true or false depending on the outcome of the check. Downstream operators in the Chain Sink can use this attribute to ignore the record or to reject it as duplicate. Per default, duplicate records are logged to a file by the ITE application, for further manual inspection. The record deduplication uses the Bloom Filter operator provided in the toolkit. You can disable this feature completely via an ITE configuration parameter. If you use it, you need to configure certain aspects of the filter like the expected number of records, the maximum acceptable probability for false positives or the usage of partitions for the filter internal housekeeping. The filter saves it internal state to disk for recovery purposes, and it participates in the ITE housekeeping mechanism, to periodically evict old records from the filter. If you use the partitioned filter configuration then the housekeeping evicts the checkpoint files only and the Bloom Filter operator evicts old records from the filter during the file processing automatically.
To identify a record, the filter uses a hash value provided in a certain attribute of the record. You need to implement the calculation of this value. This should be done in the Transformer component of the ITE application. See the documentation on the transformer for more details.
Custom correlation functions
Currently the record deduplication is the only built-in correlation function. If your use case requires other correlations like aggregations, record stitching or sequence validation, you can implement this functionality in the Custom Context. If you use ITE variant B, you can configure the application to use multiple contexts partitioned by a certain record attribute you need to set in the Transformer component. In variant C you only have one context per subset of chains. If you need to parallelize processing in this case, you can use the Streams UDP feature to do so. When you implement custom correlations, you need to take care of persisting results on your own. For example, if you implement an aggregation per subscriber, and want to emit events in case certain thresholds are crossed, you can simply add a FIleSink to store the events in a file, or use the Streams import and export mechanism to forward the event to other Streams jobs.
The Custom Context can participate in the checkpointing mechanism supplied by the ITE application. This allows you to persist the state of your correlation logic in order to survive outages. The interface you have to implement in this case, is described in the chapter regarding developing applications.