
ChainSink
The Chain Sink component handles the storage of the records, processed in the previous components.
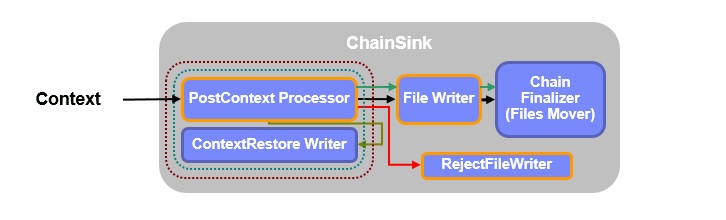
The ITE application does file to file processing. Each input file results in one or more output files, which can be picked up by other applications for further processing. The Chain Sink performs the writing of the output files and supports you with formatting the files. Optionally you can implement additional custom logic in the chain sink, if required by your use case. It also creates log files, containing statistics about the file processing. The most important components of the chain sink are described below.
FileWriter
This component actually handles writing data to the output files. You can configure the directories for the output files via configuration parameters. Output files can be grouped in subdirectories in several ways. For example you can configure the File Writer to create a new subdirectory every day, to hold the output files generated during the day.
The file writer operates in one of three configurable modes. In the recordFile mode, it simply creates one output file per processed input file. The file is CSV formatted and each line contains one record, the attributes are separated by a comma. In the tableFile mode, the FileWriter can create multiple CSV output files per processed input file. Use this mode if you want to load the processed records to multiple or different database tables, for example. In this scenario you can create one output file per target table. They can contain data from the same records with different layout, or only subsets of the processed records. The content of the table files depends on the transformation you have implemented in the Transformer or the PostContextProcessor. For more information about transformations, see the description of the transformer component. The third mode of operation is the custom mode. If this mode is selected, you can implement your own storage logic in a certain composite operator.
The mode you choose has some implications on other configuration parameters in the transformer and the chain sink components.
PostContextProcessor
This optional component can be used to implement additional business logic, which needs to be applied after the Group processing has been done. You can implement that logic in a certain composite operator. A common scenario is to evaluate the result of the record deduplication, performed as part of the context processing. Records marked as duplicates can be ignored or rejected in the PostContextProcessor according to your use case.
You can also implement record and table transformations in the PostContextProcessor, similar to transformations implemented in the Transformer. Implementing transformations here, instead of in the transformer may result in slightly better performance, depending on the type of transformation. Choose the location that best fits your use case,